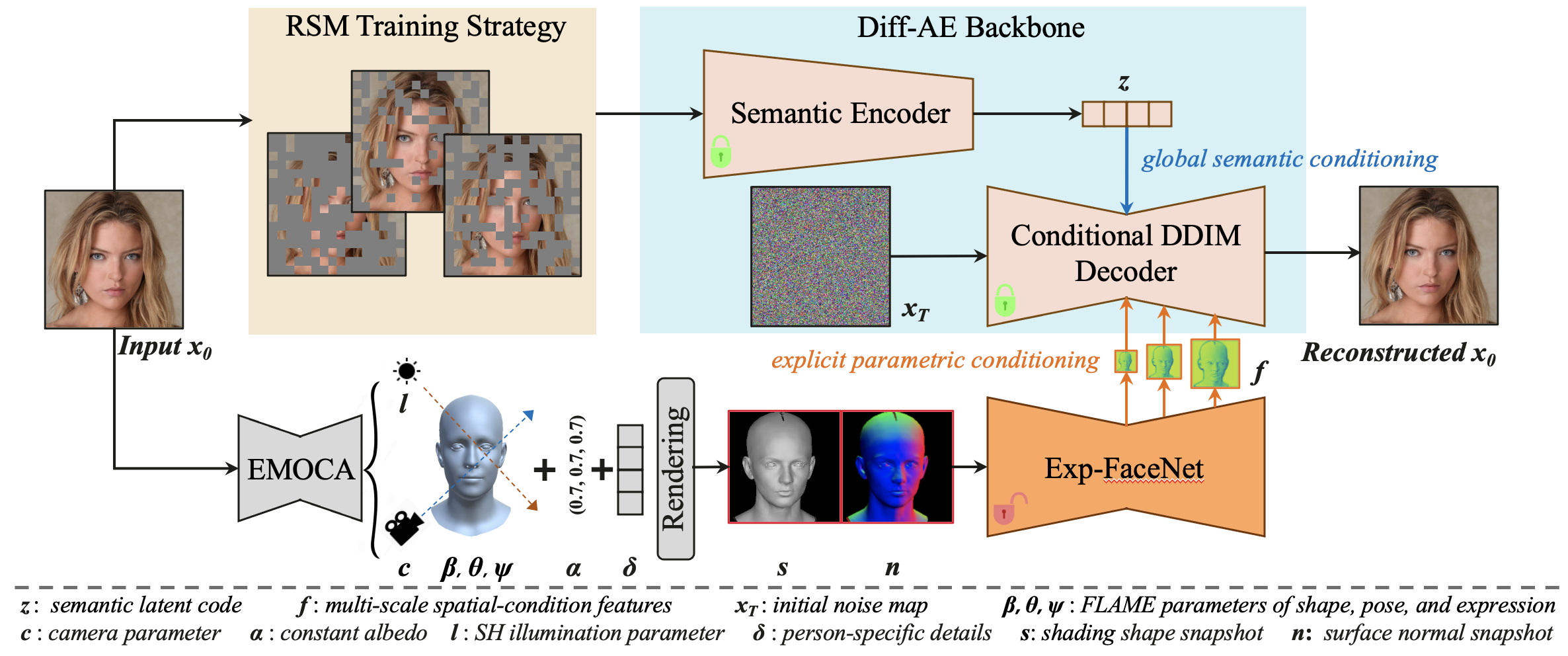
Our DisControlFace can realistically edit the input portrait corresponding to different explicit parametric controls and
faithfully generate personalized facial details of an individual.
Our model also supports other editing tasks, e.g., inpainting and semantic manipulations.